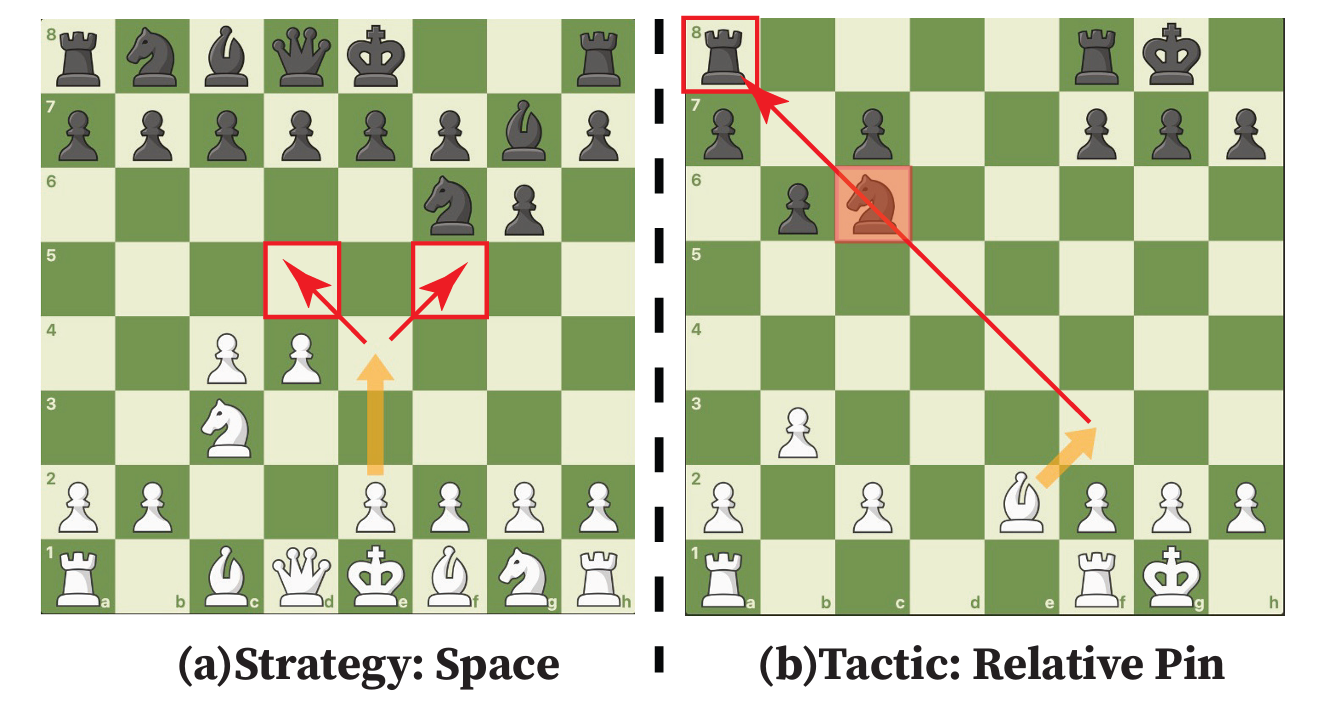
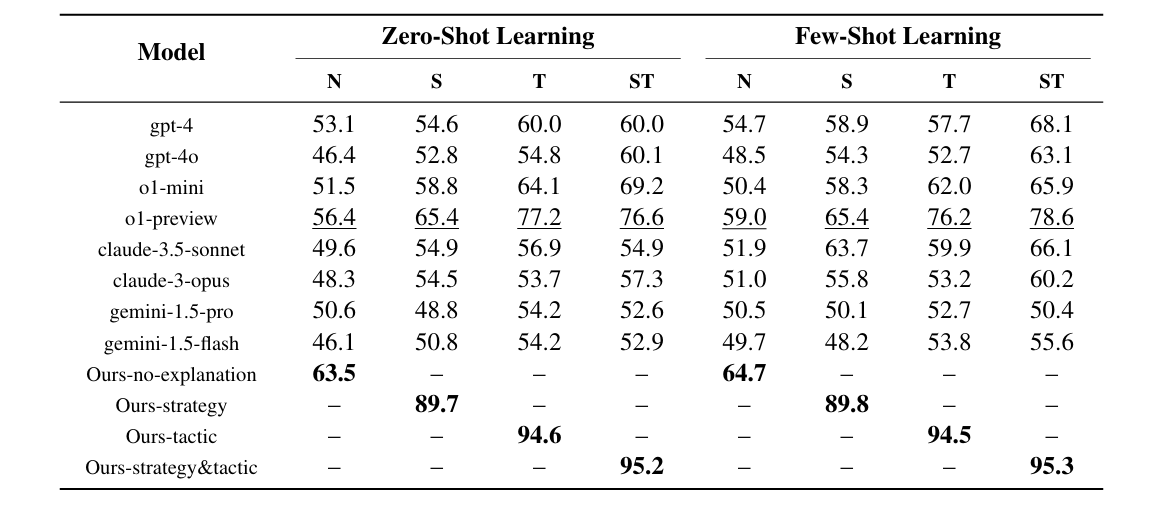
Reasoning is a central capability of human intelligence. In recent years, with the advent of large-scale datasets, pretrained large language models have emerged with new capabilities, including reasoning. However, these models still struggle with long-term, complex reasoning tasks, such as playing chess. Based on the observation that expert chess players employ a dual approach combining long-term strategic play with short-term tactical play along with language explanation, we propose improving the reasoning capability of large language models in chess by integrating annotated strategy and tactic. Specifically, we collect a dataset named MATE, which consists of 1 million chess positions with candidate moves annotated by chess experts for strategy and tactics. We finetune the LLaMA-3-8B model and compare it against state-of-the-art commercial language models in the task of selecting better chess moves. Our experiments show that our models perform better than GPT, Claude, and Gemini models. We find that language explanations can enhance the reasoning capability of large language models.




@article{wang2024explore,
title={Explore the Reasoning Capability of LLMs in the Chess Testbed},
author={Wang, Shu and Ji, Lei and Wang, Renxi and Zhao, Wenxiao and Liu, Haokun and Hou, Yifan and Wu, Ying Nian},
journal={arXiv preprint arXiv:2411.06655},
year={2024}
}